Misleading A/B testing is simple
by Rostyslav Mykhajliw Founder of TrueSocialMetrics.com ~ 4 min
Classic
The classic A/B testing is a distribution between a different states. Let’s start from a general sample everyone uses. We have a site with a signup button, currently it’s blue, but we want to test a new color red.

Then we allocate there some traffic, and waiting for some some. There’s a simple calculators for statistical significance.
Option A: 50k visitos - 500 signup
Options B: 50k visitors - 570 signups - winner
B is a winner it’s a clear. More signup’s, statistical significance.
A new classic apple to oranges
Wait a bit! What we’re releasing something new. For example, we’re adding a button “demo” for overviewing step-by-step guide through the product. 
If we follow a simple logic of A/B testings - it doesn’t work! Because we cannot compare apples to oranges. We cannot compare nothing to something! It’s totally incorrect. If there’s no demo button, so users may get a worse experience than those who have this option. But this option may only help users who already interested in product or already stated to user the product recently. Even if you have millions of traffic you cannot say how it works in a few hours/days because results may be postponed in time.
For a new functionality should be released linear as enteral release process. Only then then after sometime we may look on it and figure out whether it had some impact on customer experience or not, but tracking business metrics. A/B tests are NOT applicable for a new functionality.
AA/BB tests confidence
Go back to the first sample with signup button. If our guess is correct we can add more A options and more B option and nothing changed, because B can still win the battle.
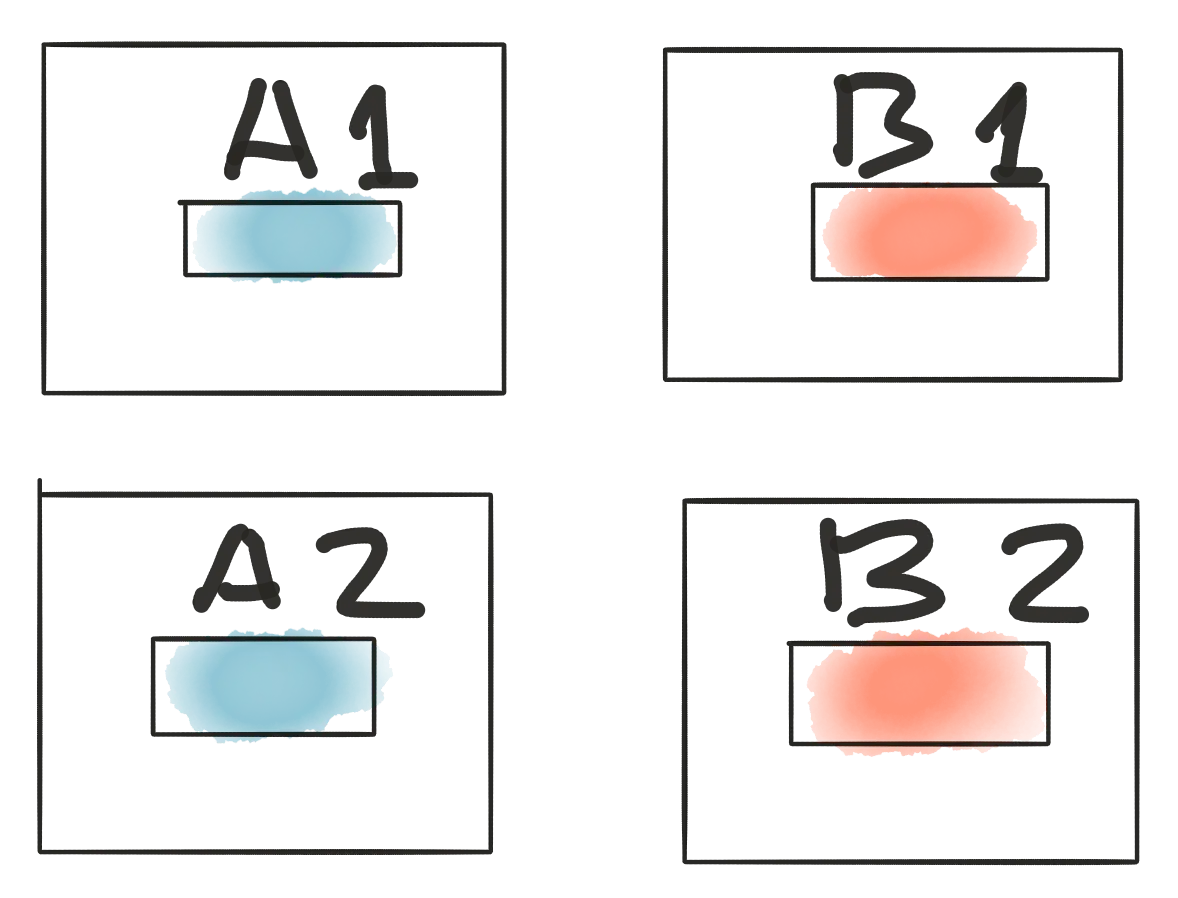
Then look at results:
A1: 50k visitos - 500 signup
A2: 50k visitors - 580 signups - winner
B1: 50k visitors - 570 signup - winner
B2: 50k visitors - 500 signups
WHAT! WHAT! WHAT! You can say it’s impossible but this situation show difference if visitors allocation takes effect on tests results. And this results are showing stable 95% statistical significance but low confidence.
Adaptive testing
If we go back to the begin of article we will notice a huge traffic 50k visitors and 500 transitions required to receive a meaningful results. However not all the pages have this possibilities. Not all the startups are good enough to generate such a traffic, or it may be a low traffic pages like settings/billings etc. For all those cases classic a/b testings will takes huge amount of time to collect data months/half of year or so. The next drawback of general approach is at least 50k visitors (from 100k allocated to test) were get worse customer experience. So we’re waiting for a long time and loosing customers due to allocation to a “loosing” test. Does it make any sense ? In healthcare doctors crossed across the case issues, but in a table was people’s life’s. If we make a test during witch 50% patiences are dying due to “not-tested-yet-care”. And it’s fucking crazy. Here’s a guy Marvin Zelen who came up with idea of Adaptive testing, called now Zelen’s design.
In short words
Let’s imagine we have 2 possibilities: red and blue balls, so statistically it is 50% probability.

For example we randomly allocate visitor to “blue” and “blue” is a better experience because we got purchase. In this case “blue” is winning, that’s why we adding an extra “blue” ball to the pool.

As result probability changed “red” - 33% and “blue” - 67%
Sounds good! But the next visitor with “blue” do nothing. So “blue” is loosing, that’s why we have to remove one “blue” ball from pool and we got our previous state.
Pluses:
+ works for small amount of traffic
+ adaptively provides better care for users
Minuses:
- requires developers works to figure out winning/losing tests in the process of testing
Concussions
- Classic A/B testing doesn’t work for a new features because you cannot test nothing with something
- Commonly A/B tests are NOT representative even if your analytics says they’re
- AA/BB approach helps to check A/B test results
- Adaptive testing is super useful for small traffic but requires hand-work to figurer goals
When you’re ready to rock your social media analytics
give TrueSocialMetrics a try!
Start Trial
No credit card required.
Continue reading
Measuring and Improving Adwords Campaign

How Oreo Rocks in Twitter: Using Content Segmentation for Tweets Analysis

The Most Viral Type of Pins: Barney’s on Pinterest

Schedule tweets with TrueSocialMetrics
